■ PostgreSQL 이중화(Pgpool2+Watchdog) Failover와 Failback
▶ 지난 포스팅에 이어 Auto Failover 테스트와 Failback 작업을 진행해 보겠습니다.
▶ pgpool-II version 4.1.4 버전을 사용하였습니다.(Ubuntu 22.04 Repository에 등록된 패키지 버전입니다. 2022년 11월 기준)
▶ pgpool2과 연동하여 사용한 Watchdog 버전은 5.16 버전입니다.
▶ 구성 환경은 Ubuntu 22.04 LTS 버전에서 PostgreSQL 14.5 버전을 apt install 한 환경입니다.
▶ Primary+Slave 2개 DB-Node로 구성 테스트 결과입니다. pgpool에서는 3개 DB-node 이상을 권장하고 있으며, 2개 Node로 구성시 동작이 원활하지 않음을 확인하였습니다. 2개 DB-Node로 이중화 구성하는 방법과 테스트는 참고용으로만 사용하시기 바랍니다.
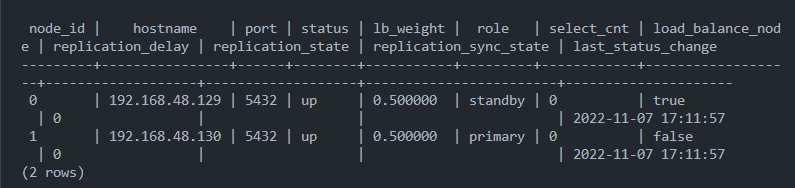
1. 정상 상태 확인



2. Master 서버 장애(Auto Failover 테스트)
1) 사례1. Master pgpool 장애
- Master 서버의 Postgresql은 기동 된 상태에서 pgpool만 장애가 발생한 상황입니다.

- Master쪽 pgpool이 다운되었다가 일정 시간(health check) 후 다시 기동 하면 VIP가 Salve로 넘어갑니다.
- Master Postgresql Down > Master Pgpool Down > Master Pgpool Start 순서로 진행해야 VIP가 Slave로 넘어갑니다.
- Primary pgpool이 다운되면 Postgresql Master와 Slave는 유지되나 VIP가 활성화되지 않아 VIP를 이용한 서비스는 불가합니다.
- VIP의 failover 기능은 Primary 서버와 Standby 서버에 pgpool이 기동 되어 있어야 합니다.
pgpool.net에 "VIP will not be brought up in case the quorum does not exist."라는 내용이 있습니다.
- VIP가 Slave로 넘어가도 pgpool에서 DB Wirte는 LB 처리되어 서비스는 정상 운영되었습니다.
- DB노드가 최소 2개가 기동된(의사결정 정족수 만족) 상태여야 VIP를 이용한 서비스가 정상 동작하는 하는 것이 확인됩니다.
- 3개 DB-Node 운영시 아래와 같이 Slave1, Slave2가 모두 다운 되어도 VIP가 활성화되는 것을 확인하였습니다.

2) 사례2. postgresql 장애
- Pgpool이 기동 된 상태에서 Master 서버의 PostgreSQL을 다운시켰을 때


- Slave 서버가 Primary DB로 승격되고 VIP를 이용한 서비스(Port 5433)는 정상 운영됩니다.

- PostgreSQL의 경우 Primary가 Master에서 Slave로 Auto Failover 되는 것이 확인됩니다.
3) 사례3. 서버 장애
- Master 서버 OS가 Shutdown 된 상황입니다.
- Pgpool이 2대 이상 운영되지 않아 VIP가 기동 되지 않습니다. 정상적인 서비스가 되지 않습니다.
- Master pgpool에서 failover를 시켜줘야 하나 서버가 다운되어 스크립트가 실행되지 않습니다.
- Slave 서버 pgpool에서 Master server Status를 "quarantine' 변경시키고 Role은 모두 "Standby" 상태가 되어 버립니다.

- Slave 서버를 Primary로 수동 승격 시켜줘야 합니다.
touch /data/postgres14-data/promte_trigger_file.txt - 어플리케이션단에서 서비스 포트 및 IP를 Slave 서버로 변경하는 등 조치가 필요합니다.
- 3개 노드 구성시는 1대 서버 OS가 shutdown 되어도 정상 동작합니다.
3. Master 서버 복구(Failback 테스트)
- Auto Failback을 설정하지 않았기 때문에 수동으로 Master서버를 Online recovery(Slave) 작업을 해야 합니다.
- Failback은 Slave가 Primary로 운영되고 장애가 발생했던 Master 서버를 Standby로 복구하는 것을 의미합니다.
- Online recovery 작업은 기존 Master 서버에서 진행하며 기존 Slave 서버(Primary) $PGDATA 하위에 recovery_1st_stage, pgpool_remote_start 스크립트가 있는지 다시 한번 확인합니다.
1) Online recovery(Slave) 작업
- 온라인 복구의 경우 복구 대상 노드가 분리 상태여야 합니다. 즉, 장애 조치의 결과로 노드가 pcp_detach_node에 의해 수동으로 분리되거나 Pgpool-II에 의해 자동으로 분리되어야 합니다.
sudo -u postgres pcp_detach_node -h 192.168.48.121 -p 9898 -U postgres -n 0- postgres 계정으로 실행해야 합니다.(-n 옵션 뒤에 숫자는 복구할 Node 번호 입니다.)
pcp_recovery_node -h 192.168.48.121 -p 9898 -U pgpool -n 0
2) Online recovery(Slave) 정상적으로 진행되지 않을 경우(Master 서버)
2)-1. 기존 데이터 삭제
rm -f /var/log/postgresql/pgpool_status
rm -f /data/postgres14-data/archive/*
rm -rf /data/postgres14-data/main
2)-2. Master Node attach
sudo -u postgres pcp_attach_node -h 192.168.48.129 -p 9898 -U postgres -n 0
2)-3. ps_basebackup
pg_basebackup -h 192.168.48.130 -D /data/postgres14-data/main -U repluser -v -P -R -X stream
2)-4. postgresql start
4. 결론
- Pgpool2 4.1 버전으로 이중화 구성시 3개 DB-Node 이상으로 구성해야 원활한 이중화 서비스가 되는 것을 확인할 수 있었습니다.
- 2개 DB-Node 이중화 구성시 Pgpool의 Watchdog을 이용하지 않고 Keepalived를 이용한 VIP 서비스를 구성하는 사례도 있으나 직접 확인은 못해봤습니다.
- Pgpool2는 최신 4.3에서 많은 부분이 개선된 것으로 확인되니 가급적 최신 버전으로 구성을 권장합니다.
- Failback시에 Online recovery를 진행했으나 다양한 상황에서 시도 시 실패하는 경우가 다수 있었습니다. 수동으로 pg_basebackup을 이용하여 복구하는 것이 마음 편할 수 있습니다.
- 여건이 허락되어 3개 DB-node로 HA를 구성하는 것이 아니라면 VIP 이용을 하지 않고 Master 서버의 Real IP 서비스와 Slave로 Auto Failover 기능 정도를 사용하는 것이 좋을 듯합니다.
※ 참고 및 출처
https://www.pgpool.net/docs/latest/en/html/tutorial.html
https://www.pgpool.net/docs/41/en/html/example-cluster.html


댓글